

Le deuxième forum “Open d’Etat” a permis de travailler sur l’engagement 20 du Plan d’action national de la France pour une action publique transparente et collaborative, intitulé « Assurer une plus grande transparence des activités des représentants d’intérêts » et porté par la Haute Autorité pour la transparence de la vie publique. Les ateliers ont porté sur 2 sujets :
- Des cas d’usage des données du répertoire des représentants d’intérêts,
- Des exemples de datavisualisations qui pourraient être réalisées à partir du même répertoire.
Concernant le premier atelier, les points de sortie sont nombreux : assister les assistants parlementaires dans la qualification des contacts avec les représentants d’intérêts, permettre à des chercheurs l’impact des actions de lobbying sur l’élaboration des lois, donner aux associations la possibilité de s’unir pour mener des actions communes.
Le deuxième atelier a également permis de proposer des représentations de données : tableau de bord pour photographier visuellement la base, aide pour explorer les données et éventuellement détecter des incohérences, liens des responsables publics avec les différents types d’organisation sous la forme d’un réseau, carte du réseau des clients des cabinets de lobbying et une carte des affiliations des acteurs de la base.
Jeudi 24 mai 2018, Etalab, Datactivist et Vraiment Vraiment ont lancé avec la Haute Autorité pour la transparence de la vie publique la 2è édition des forums Open d’État, qui s’est tenue dans leurs locaux.
Ces rencontres régulières visent à établir un dialogue entre la société civile et les agents publics autour des engagements du plan d’action 2018-2020 de la France pour une action publique transparente et collaborative. Afin de favoriser la mise en oeuvre collaborative des engagements, ces rencontres portent sur des points précis du plan d’action.
Pour donner suite aux demandes formulées lors de la première rencontre de travailler sur la compréhension de l’action publique et le pouvoir d’agir citoyen, nous avons choisi d’aborder dans cette deuxième rencontre l’engagement n°20 du plan d’action, porté par la Haute Autorité. Son contenu : publier en open data les données du répertoire numérique des représentants d’intérêts crée en 2017, associer la société civile à son enrichissement et accompagner ses usages. Les données du répertoire permettent de mieux connaître quelles organisations exercent directement ou indirectement des actions de représentation d’intérêts (lobbying) auprès des décideurs publics (type d’organisation, coordonnées, dirigeants, clients, champs d’activités etc.), et de comprendre leurs actions et les moyens qui y sont alloués.
Préalablement à la rencontre, un kit d’appropriation a été envoyé puis distribué aux participant-e-s afin de présenter brièvement le contexte législatif entourant la création du répertoire, les enjeux du lobbying, ainsi qu’une introduction aux données du répertoiredes représentants d’intérêts, ceci afin de s’assurer qu’un niveau commun de compréhension soit partagé.
La rencontre s’est déroulée en trois temps :
- En préambule : un rappel des principes du manifeste des forums Open d’Etat, co-construit lors de la précédente rencontre (voir compte-rendu).
- Première partie du forum : une phase d’acculturation au sujet, réalisée avec l’intervention d’experts des données de représentation d’intérêts.
- Deuxième partie : un moment d’idéation autour d’ateliers pratiques pour comprendre le potentiel et les limites de ces données.
HATVP : comment rendre le répertoire plus utile et plus accessible ?

La première table ronde accueillait deux agents de la Haute Autorité pour présenter les données du répertoire : Yann Adusei, adjoint au chef du pôle communication et relations institutionnelles et Antoine Héry, chef du pôle relations avec les publics, en charge de la mise en œuvre du répertoire. L’un des défis de la création du répertoire en 2017 consistait à s’accorder sur les termes employés. Qu’est-ce qu’un représentant d’intérêts ? Qu’est-ce qu’une activité de représentation d’intérêts ? Qui doit déclarer et comment ? À ces questions qui peuvent avoir des conséquences juridiques fortes, la Haute Autorité apporte des réponses dans des lignes directrices qui décrivent en détail les critères d’inscription au répertoire et les obligations qui en découlent
Aujourd’hui, près de 1600 représentants sont inscrits au répertoire ; ils ont déclaré, pour le second semestre de l’année 2017 (juillet/décembre) près de 5000 activités. Ces déclarations doivent préciser la question sur laquelle a porté la ou les actions de lobbying (ex. : l’exploitation d’hydrocarbures), le domaine d’intervention (ex : les énergies fossiles), le type de décision publique concernée (ex : la loi) ou encore la fonction du responsable public contacté (ex : député). Toutefois le nom du responsable public consulté n’est pas demandé. Depuis le 1er juillet 2017, date d’entrée en vigueur du répertoire, beaucoup de données ont déjà été accumulées mais celles-ci présentent plusieurs limites comme l’a montré l’observatoire des multinationales. Se pose aussi la question des contrôles qui vont être progressivement exercés sur les déclarations, faut-il faire appel aux citoyens pour pointer d’éventuelles incohérences ? Enfin, l’interface actuelle du moteur de recherche reste très limitée, et comme premier axe d’amélioration, la Haute Autorité travaille à de nouvelles manières d’explorer les données du répertoire afin de les rendre plus utiles et faciles à comprendre par un public le plus large possible.
Contexte : comment enquêter avec les données du répertoire ?

Contexte est un site d’informations né en 2013 à destination des professionnels des politiques et des affaires publiques. Son fondateur, Jean-Christophe Boulanger, a expliqué que Contexte part du constat d’un manque de transparence dans les décisions publiques et le processus démocratique. Contexte est à la fois utilisateur des données sur la représentation d’intérêts mais aussi producteur puisqu’il est le premier média à avoir publié les déclarations d’intérêts de son équipe. 25 personnes travaillent aujourd’hui pour Contexte, dont 16 journalistes.
Pour aider ses lecteurs à explorer les coulisses de l’élaboration de la loi, Contexte data exploite les données brutes des sites des deux assemblées pour permettre un suivi interactif de l’activité parlementaire française. La rédaction de Contexte utilise l’interface de programmation (API) du répertoire des représentants d’intérêts pour alerter, via un bot dans leur outil de discussion interne, les journalistes sur les activités de représentation d’intérêts qui les concernent. Cela permet à la rédaction de savoir quelle entreprise a mené des actions de lobbying et de connaître par quelle agence ou cabinet elle se fait éventuellement représenter. Un journaliste de la rédaction de Contexte a expliqué que les données du répertoire peuvent être un bon aiguillon pour orienter l’enquête vers de nouvelles pistes. Selon lui, la richesse de l’enquête ne vient pas des données elles-mêmes mais de leur mélange et de leur traitement par des journalistes experts.
Transparency International UE : les enseignements du registre européen des représentants d’intérêts
Daniel Freund, responsable du plaidoyer à Transparency International EU, nous a présenté les données du registre européen des représentants. En vigueur depuis 5 ans, c’est la plus grande base de données au monde avec 12 000 organisations enregistrées.
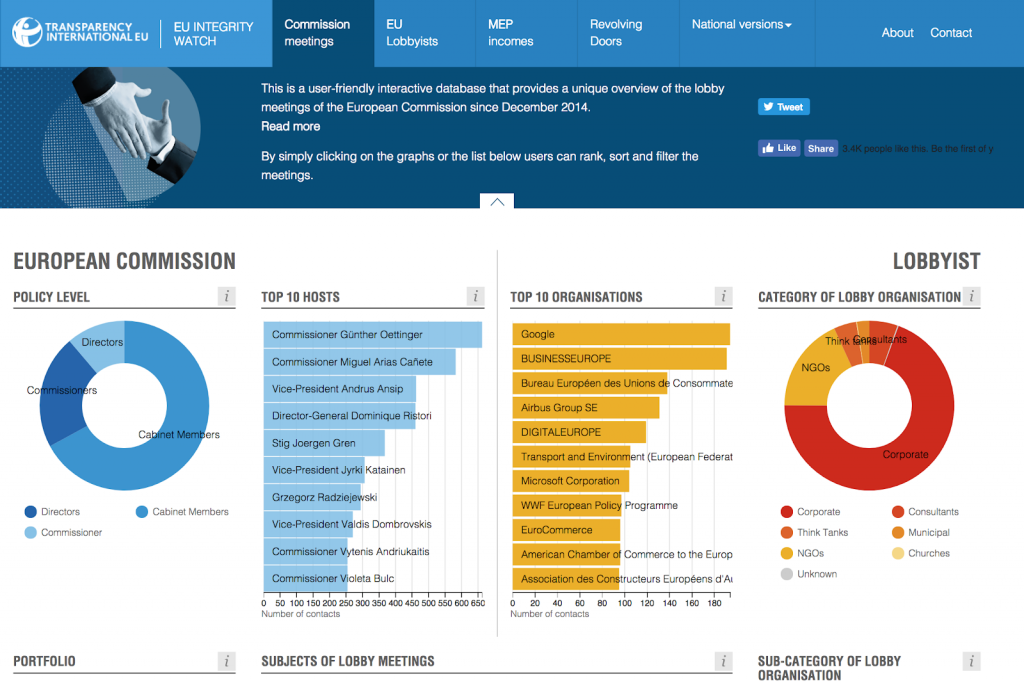
Par leur volume, ces données peuvent être très difficiles à explorer. Pour y répondre, Transparency International (TI) EU a développé Integrity Watch pour explorer le détail des réunions des représentants d’intérêts avec des élus européens ce qui permet d’explorer les coulisses du lobbying à Bruxelles. Techniquement, TI a un outil de scrapping pour télécharger les données du registre toutes les 24 heures ce qui permet de suivre en quasi temps réel l’action des lobbyistes. En activité depuis 2 ans, Integrity Watch est utilisé quotidiennement par des chercheurs et des ONG. Du fait de l’exposition du site aux yeux du public, certains commissaires ne prennent pas certaines réunions. Avec ce site, TI veut s’assurer que les décisions prises soient prises pour l’intérêt général et non pour les intérêts particuliers. Les représentants des Etats au Conseil de l’Union Européenne publient leurs réunions, TI veut étendre ce système aux eurodéputés. Transparency International a aussi développé une version d’Integrity Watch pour la France qui s’appuie sur les données de la HATVP.
Pour obtenir en France le même niveau de transparence qu’au niveau européen avec une publication des participant-e-s aux réunions et un reporting en quasi temps réel, Daniel Freund explique que l’on peut s’appuyer sur ce cas pour faire du plaidoyer. Aujourd’hui, la déclaration des réunions n’empêche pas les personnes concernées de travailler. Le contexte européen a aussi beaucoup aidé à l’époque avec le scandale d’un ancien commissaire, auquel des représentants des lobbys du tabac auraient versé de l’argent.
Atelier 1 – scénarios : Ouvrir les données du répertoire des représentants d’intérêts, pour quoi faire ?

Le premier atelier a eu pour objectif de construire des scénarios d’usage avec les données du répertoire afin de comprendre le potentiel des données, d’identifier les croisements qui permettront de les enrichir et de pointer des manques.
Un premier groupe cherchait à comprendre comment étudier les pratiques du lobbying à partir des données du répertoire. Ils ont montré que les données permettent déjà des analyses sectorielles pour comprendre les montants engagés par rapport à la thématique mais aussi aux types de décision publique. Pour réaliser ce projet, la complétude des données est cruciale. Or, de nombreux représentants ne figurent pas encore dans le répertoire, ce qui réduit la portée des analyses qui pourraient être faites sur la réalité de la représentation d’intérêts.
Un deuxième groupe a identifié trois cas d’usage pour les données du répertoire en désignant des personas, des personnages imaginaires représentant un groupe type. Le premier cas d’usage portait sur les assistants parlementaires qui pourraient mieux qualifier les sollicitations des parlementaires en détectant directement les représentants d’intérêts – comme le suggère la Haute Autorité dans son rapport d’activité 2017 – et en retraçant les contacts déjà établis au profit d’un bénéficiaire. Le deuxième cas d’usage portait sur l’apport des données du répertoire pour des chercheurs qui souhaitent mesurer l’influence des lobbys sur l’élaboration des lois. Enfin, le troisième cas d’usage portait sur les associations qui pourraient utiliser les données pour coordonner leur action, répondre à des actions de lobbying et constituer des “consortium” de représentation d’intérêts pour porter une parole commune.
Atelier 2 – visualisation : comment représenter les données du répertoire ?
Le second atelier permettait aux participant-e-s de se projeter sur l’usage direct des données du répertoire. Que peut-on montrer avec ces données ? Sur quel support se baser, et quel type de représentation de données utiliser ? Les participant-e-s se sont appuyé-e-s sur le kit d’appropriation qui présentait une vue schématique des données ainsi que sur le Dataviz Project qui présente l’éventail des formats de visualisation existants selon leur fonction (comparaison, cartographie, corrélation…) et selon le type de données exploité. Après une phase d’idéation, trois groupes ont été constitués, chacun travaillant sur une thématique particulière.
Le premier groupe a imaginé un tableau de bord pour photographier visuellement la base, aider à explorer les données et éventuellement détecter des incohérences. Leurs réflexions ont montré qu’il était possible de varier les formats et les angles d’entrée dans les données : une carte pour localiser les représentants et les activités sur le territoire avec la possibilité de rendre visible en rouge les représentants qui n’auraient pas rempli leur fiche, plusieurs graphs pour montrer l’activité des représentants d’intérêts avec par exemple l’idée d’un diagramme de Sankey pour montrer les relations entre les différents acteurs et aussi en éditorialisant en fonction de l’actualité pour élargir le public s’intéressant à ces données.
Ce premier groupe a en outre considéré que les visualisations devaient aussi montrer que le répertoire est un travail en cours en présentant, par exemple, des tops des représentants d’intérêts qui enregistrent bien leurs activités et en estimant et visualisant (par une jauge) le pourcentage de représentants d’intérêts qui n’ont pas encore fait leurs déclarations d’activités.
Le deuxième groupe travaillait sur l’empreinte de la représentation d’intérêts dans la décision publique. Le premier prototype de visualisation part des responsables publics pour voir leur lien avec les différents types d’organisation sous la forme d’un réseau (la taille du lien montrant l’intensité des échanges et la taille de la bulle matérialiseraient les montants engagés) ce qui permet de retracer à travers le temps l’influence des différents acteurs dans la fabrique de la loi. Le deuxième prototype part du bénéficiaire (par exemple, une entreprise dont les intérêts sont représentés par plusieurs cabinets) pour montrer, à travers le temps, sur quelles législations elle est intervenue.
Le troisième groupe est allé au-delà du prototypage pour produire (en moins d’une heure !) une carte du réseau des clients des cabinets de lobbying et une carte des affiliations des acteurs de la base (ex. : Auchan adhère à la fois au MEDEF et à l’Union des Annonceurs). Ces visualisations permettent d’avoir une vue panoramique des données de la base qui dépasse les limites d’explorations du moteur actuel de recherche sur le site de la HATVP.
La suite
Pour la HATVP, cet atelier a permis de faire se rencontrer une diversité des réutilisateurs et d’envisager des usages possibles des données du répertoire numérique. En priorité, elle mettra à disposition, dans le courant de l’été, des utilisateurs un moteur de recherche avancée permettant d’en explorer la totalité des données. Elle facilitera également, dans les prochains mois, l’exploitation et l’enrichissement du répertoire à travers la mise à disposition du code source de celui-ci.
A moyen–terme, dans une démarche d’ouverture analogue à celle du forum Open d’État, elle souhaite développer des outils de data visualisation qui permettront d’avoir une vision plus fine des représentants d’intérêts et de leurs activités.
Le Forum Open d’État suivant?
Le forum Open d’État #3 a eu lieu le 09 juillet 2018 sur le thème de la science ouverte.