

En amont de l’évènement, des jeux de données portant sur des thématiques susceptibles d’inspirer les participants ont été proposés ici, parmi lesquels des données ouvertes récemment sur data.gouv.fr. Dans ce cadre, des datascientists, des codeurs, des chercheurs, et des designers ont travaillé ensemble, accompagnés de membres de l’équipe d’Etalab.
Voici la présentation des projets issus d’une journée de travail à l’open data camp :
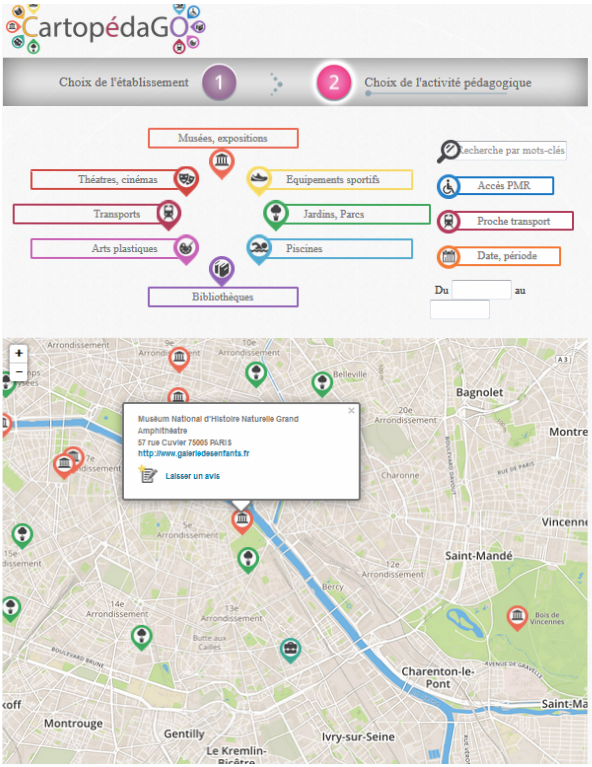
- CartoPedago
L’équipe Sopra Steria, conseillée par Michèle Dreschsler (Inspectrice IEN et Conseillère TICE auprès du recteur d’Orléans-Tours), a conçu et réalisé l’application CartoPedago. Il s’agit d’une application permettant aux enseignants de découvrir les activités et les sorties en lien avec leur programme pédagogique. L’interface, permet de sélectionner dans un premier temps l’établissement scolaire et la classe de l’enseignant puis visualiser l’ensemble de l’offre de service géo-localisée, en raffinant la recherche à l’aide de filtres. Un module permettant de noter les activités a également été développé pour permettre aux enseignants de partager leurs expériences.
Voici les jeux de données utilisés, disponibles sur data.gouv.fr:
– Les lieux de diffusion du spectacle vivant en Île-de-France
– Rendez-vous aux jardins
– Les Etablissements « Tourisme & Handicap »
– Adresse et géolocalisation des établissements d’enseignement du premier et second degré
- Open-Carburants
La première fonctionnalité du projet Open-Carburants développée lors de l’Open Data Camp a été un comparateur de stations-services autour d’une adresse. Ceci a été possible grâce au croisement de 3 sources de données ouvertes :
– L’adresse a été géo-codée grâce à la Base Adresse Nationale
– Les stations-services, leur géolocalisation et leur prix ont été récupérés de la base ‘Prix des carburants’
– Les distances et temps de parcours vers les stations-services les plus proches ont été calculés grâce à Open source routing machine, un moteur de calcul d’itinéraire open source reposant sur les données OpenStreetMap.

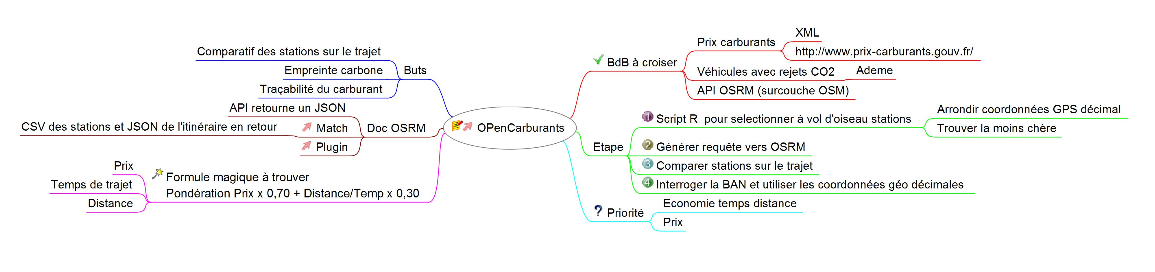
Le travail autour de ces données de transport a mis en évidence des pistes d’usage possibles:
– Le calcul de la meilleure station-service sur un itinéraire grâce à la fonction match d’OSRM.
– Le calcul émissions de CO2 et polluants grâce à l’intégration des données de l’ADEME sur les véhicules commercialisés en France.
– Le rendu d’informations sur l’origine, l’acheminement et le traitement des hydrocarbures contenus dans les carburants grâce au croisement des données issues des Douanes Françaises, de Marine Traffic et du Ministère de l’Ecologie du Développement Durable et de l’Energie.
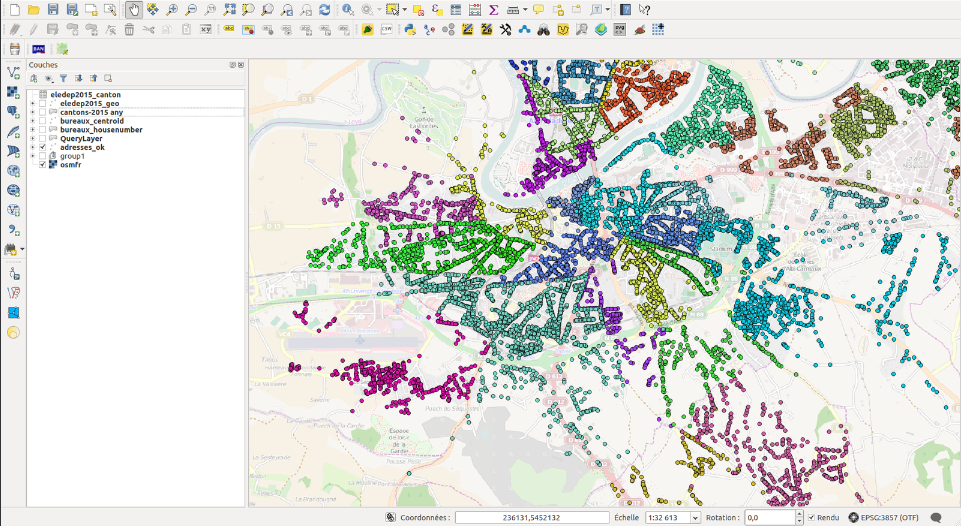
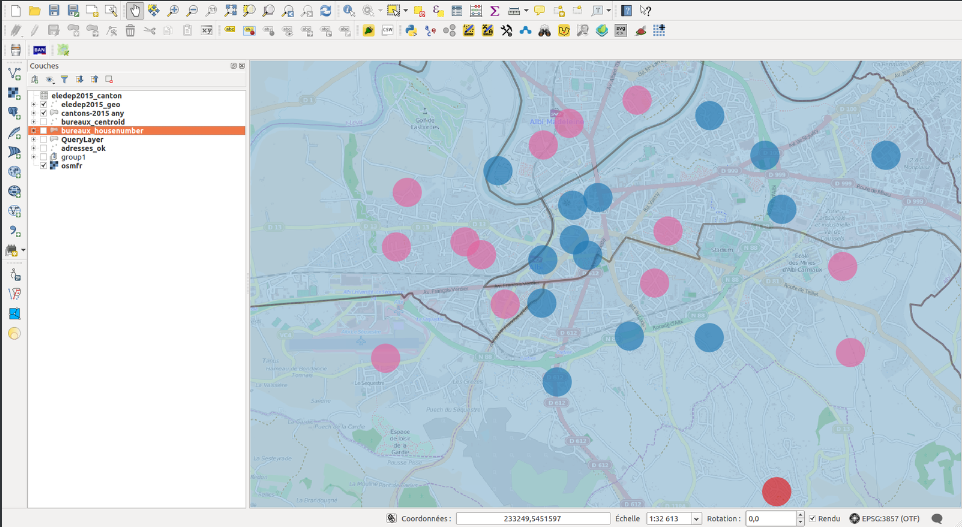
- Contour des bureaux de votes
Le Ministère de l’Intérieur a récemment publié les résultats électoraux par bureau de vote depuis 1999. Pour permettre une représentation cartographique de ces résultats et illustrer les contours des bureaux de vote, il est nécessaire de disposer des adresses des inscrits à chaque bureau de vote. Ces données ne sont pas actuellement disponibles en open data sur l’ensemble du territoire, mais quelques collectivités les ont publiées lorsqu’elles étaient disponibles sur leur portail open data.
Les données de départ sont donc les listes électorales de 4 départements, dans lesquelles les données personnelles ont été supprimées pour ne conserver que l’adresse, le numéro de bureau de vote, de canton et le code INSEE de la commune. Elles ont ensuite été géocodées à l’aide de l’API publique de géocodage mise en place par Etalab sur le portail de la Base Adresse Nationale.
Les tentatives de dallage de chaque bureau de vote n’ont pas donné de résultat exploitable (trop de chevauchement dans les polygones générés), c’est donc le « centroid » des adresses des inscrits qui a été calculé pour symboliser leur localisation, et permettre une visualisation cartographique des résultats par bureau de vote. La présentation des résultats est disponible ici.
- Text-mining sur la consultation ‘Projet de loi pour une République numérique’
Les consultations menées en ligne par les administrations engagées dans une démarche de gouvernement ouvert génèrent des contributions parfois massives, difficiles à analyser rapidement par des êtres humains. L’objectif du projet était ici de tester des pistes d’automatisation de cette analyse, à partir des techniques de text-mining.
Pour commencer, les contributions recueillies sur le site de la consultation du ‘Projet de loi pour une République numérique’ ont été moissonnées en utilisant l’API JSON du site. L’évolution heure par heure des contributions sur les 4 derniers jours de la consultation a ainsi été rendue disponible dans un dépôt git, accessible à tous.
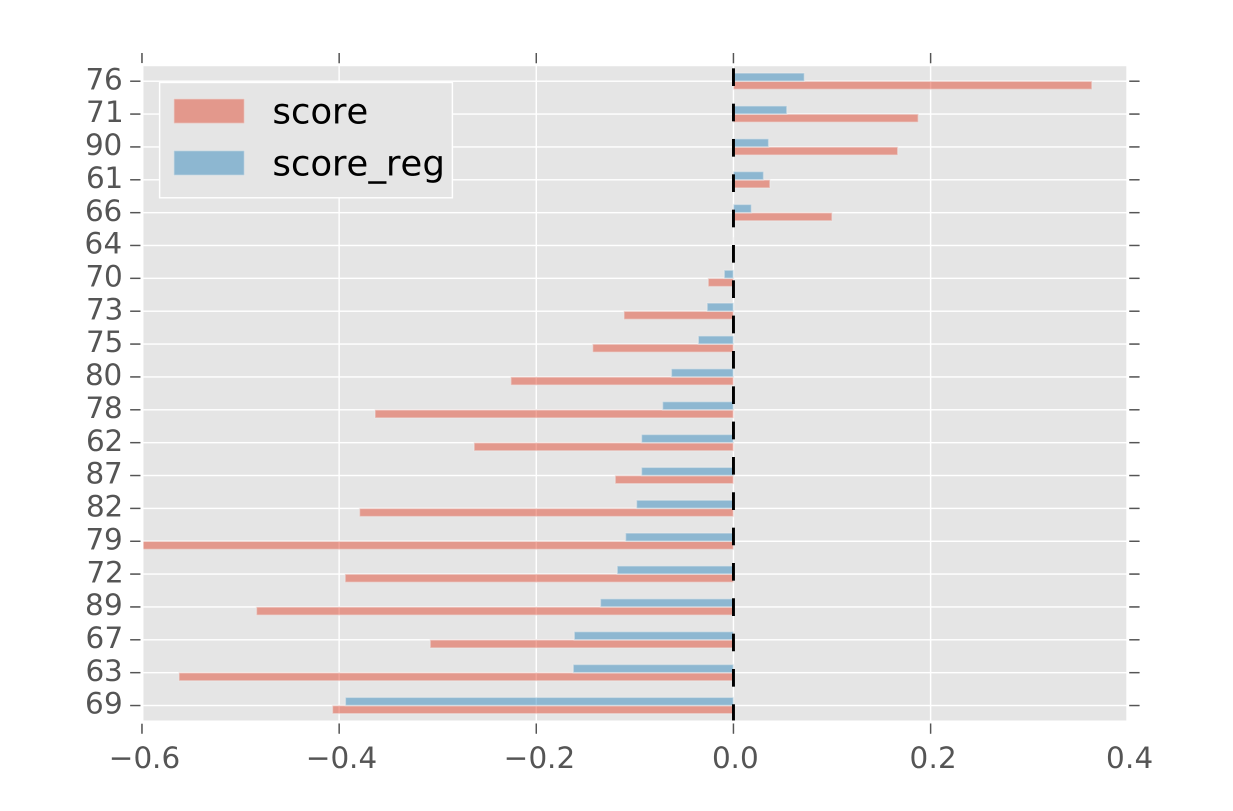
Puis, des statistiques descriptives ont été développées en guise d’analyse exploratoire des données. Ci-dessous, un comparatif, pour les 20 articles les plus commentés, du score ‘brut’ en rouge ((arguments pour – arguments contre) / (arguments pour + arguments contre)) avec le score ‘normalisé’ en bleu (en tenant compte du nombre total de personnes ayant commenté l’article), qui permet de donner un score plus représentatif.
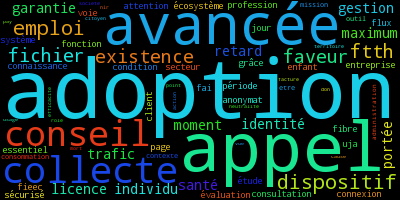
Par ailleurs, le module pattern pour Python a été utilisé pour générer des nuages de noms et d’adjectifs correspondant aux arguments pour et contre les articles proposés pour le gouvernement, l’objectif étant d’identifier les thématiques récurrentes des partisans et des opposants au projet de loi. Voici quelques exemples de résultats, dont il faut rappeler qu’ils dépendent des règles choisies par l’équipe dans l’algorithme de filtrage des données (par exemple méthode de calcul de l’importance des mots, suppression des termes communs aux contributions favorables et défavorables…).
Pour:
Contre:

[:]