

Le 23 février 2015, Sciences Po a accueilli dans ses locaux parisiens l’open data camp élections co-organisé par le Centre de données Socio-Politique (CDSP) de Sciences Po, le ministère de l’Intérieur ainsi que la mission Etalab rattachée au Secrétariat Général pour la Modernisation de l’Action Publique (SGMAP).
De nouvelles données électorales mises à disposition
Le centre de données socio-politiques (CDSP) de Sciences Po a rendu public en Open Data sur data.gouv.fr un ensemble de données historiques couvrant les élections législatives, présidentielles, régionales et cantonales depuis 1958. Le fonds de résultats électoraux du CDSP est régulièrement enrichi afin de fournir à la communauté scientifique et à un public plus large des ressources nécessaires à l’analyse des évolutions de l’offre politique et des élections.
Le ministère de l’intérieur a quant à lui mis à disposition sur la plateforme data.gouv.fr les données relatives aux candidats aux élections départementales pour l’année 2015 ainsi que les contours des cantons électoraux départementaux 2015 dans un format réutilisable (shapefile). Les réutilisateurs de données pouvaient compter sur les nombreux fichiers mis à disposition par le bureau des élections du ministère couvrant l’ensemble des élections depuis 1992 jusqu’à nos jours.
Enfin, l’Institut National de l’Audiovisuel (INA) a mis à disposition des participants de l’évènement un corpus comprenant près de 25 000 sujets d’actualité télé et radio couvrant 10 années d’élections nationales et locales. Tirés des JT diffusés sur 20 chaines TV et 6 radios, tous les sujets ont été précisément décrits et annotés par les documentalistes de l’INA. Toutefois, l’INA a précisé en amont de l’open data camp que ces données n’étaient actuellement pas ouvertes et qu’elles étaient mises à disposition spécialement pour l’évènement.
Les projets présentés
- Données socio-démographiques et comportement électoral (par @vinpons et @ineslevy de la société Liegey Muller Pons, @sl956 et @blaquans):
Ce groupe de travail a utilisé les données du recensement sur le secteur d’activité de la population active par commune, les données sur les élections présidentielles par commune afin de les apparier en fonction du recensement le plus proche (élection de 1981 appariée au recensement de 1982, etc.).
Ces appariement ont permis de mesurer:
- l’effet par commune de la part d’ouvriers dans la population active sur le vote PS:
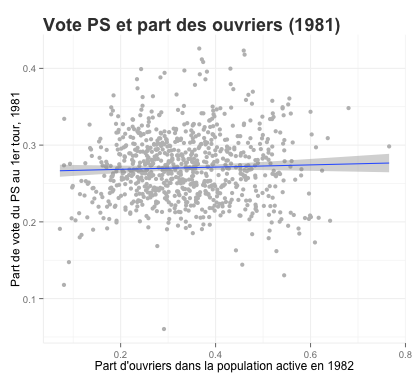

- L’effet par commune de la part de la population active travaillant dans l’industrie sur le vote PS:
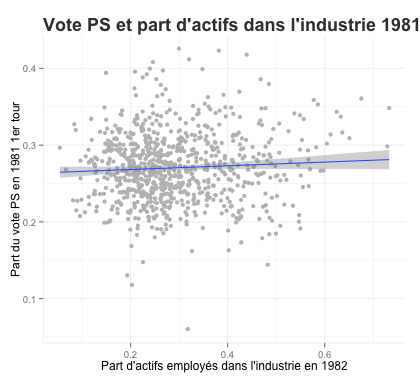
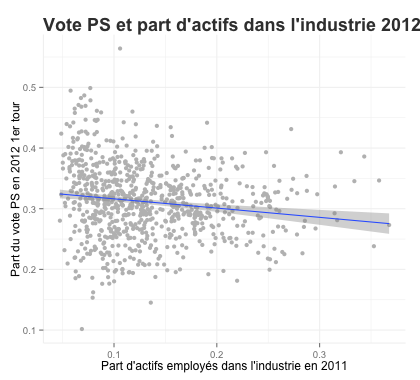
- L’effet de l’évolution du secteur d’activité sur l’évolution du vote PS entre 1981 et 2012:
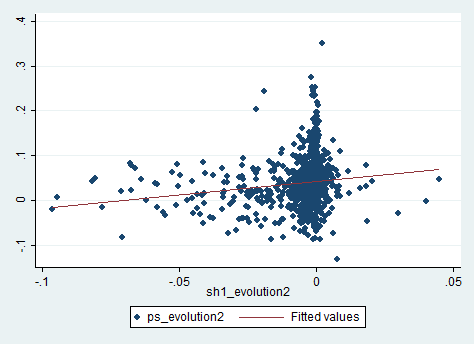
- l’effet de la part de l’industrie sur le vote PS de 1981 à 2012:

- Le réseau des données de l’INA (par @coulmont)
Lors de l’open data camp élections, un représentant de l’INA (Gautier Poupeau, @lespetitescases) proposait de travailler sur les méta-données politiques des journaux télévisés (données uniquement disponibles dans le cadre de cet évènement et pas accessibles en open data), le groupe de travail a regardé s’il était possible de repérer des proximités entre individus à partir des co-participations aux reportages, interviews, etc…
Le groupe de travail a retenu comme lien significatif les liens qui apparaissent au moins trois fois plus fréquemment que ce qui serait attendu si les individus étaient répartis au hasard dans l’espace médiatique :

Les couleurs sont liées à des “communautés” repérées à l’aide de l’algorithme WalktrapCommunity. Rien de surprenant, mais c’est assez illustratif, et assez simple à faire.
- Géolocalisation des lieux suscitant l’intérêt médiatique en rapport avec les élections (un journaliste de la rubrique Désintox de Libération (@B_Bouthier), deux étudiants en sciences sociales, un data scientist d’Etalab (@AlexisEidelman), un chercheur/dévelopeur du CEVIPOF, un statisticien et une personne de l’INA (@lespetitescases)):
L’idée de départ a été de travailler sur les descripteurs des notices de l’INA, géolocaliser par élection les lieux qui ont fait l’objet de l’intérêt médiatique et mettre en parallèle les résultats des élections dans ces différents lieux afin d’étudier une éventuelle corrélation entre l’intérêt médiatique et les modalités de vote (en particulier l’abstention).
A l’issue de la journée, le groupe de travail est parvenu à réaliser la première partie du travail, le temps manquant pour réaliser la seconde.
Voici quelques copies d’écran de l’application réalisée :
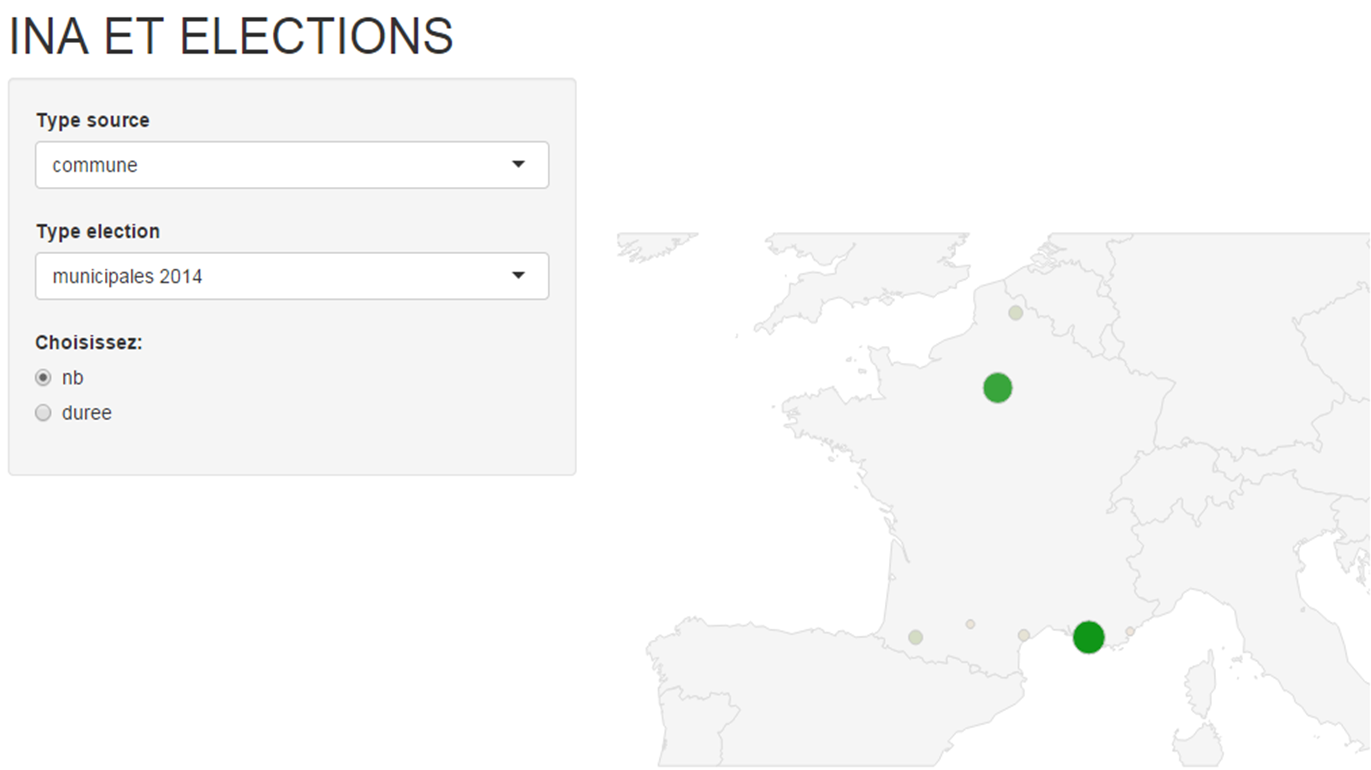 Figure 1. Granularité « commune »pour les élections municipales de 2014
Figure 1. Granularité « commune »pour les élections municipales de 2014
On remarque qu’en dehors des grandes métropoles que sont Paris, Marseille et dans une moindre mesure Toulouse (absence très nette de Lyon), les médias se sont intéressés aux communes gagnées par l’extrême droite (Hénin-Beaumont, Fréjus, Béziers) et à Pau (François Bayrou).
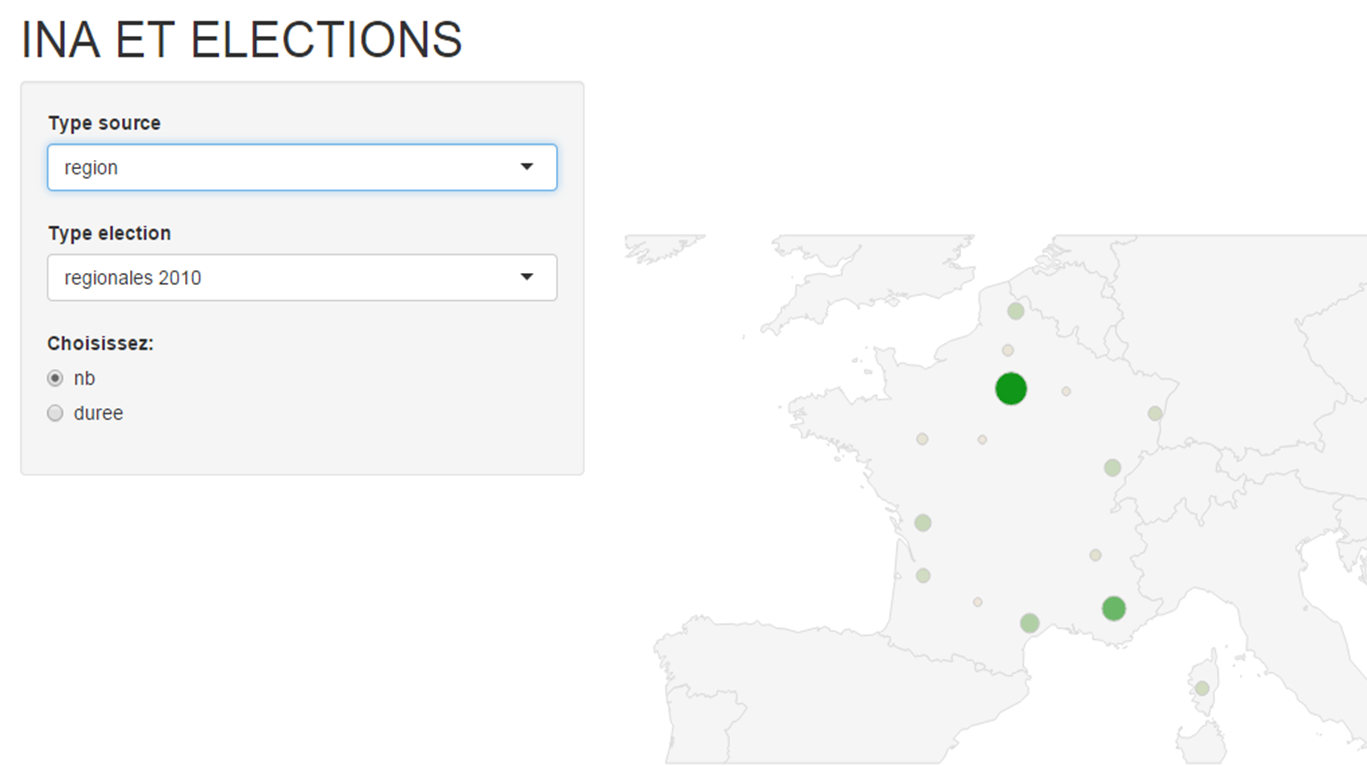 Figure 2. Granularité « Région »pour les élections régionales de 2010
Figure 2. Granularité « Région »pour les élections régionales de 2010
On voit que l’essentiel de l’intérêt médiatique se porte sur les régions Ile-de-France et PACA avec un détachement pour le Languedoc-Roussillon qui s’explique par la sécession du PS de Georges Frêche.
Comme l’avait déjà montré le projet OT Media, les métadonnées de l’INA constituent un bon moyen de mettre en place un observatoire des médias. Leur mise à disposition sous une licence libre permettrait d’en démultiplier les usages qui sont potentiellement gigantesques.
- Qui se ressemble s’assemble (ou pas) : Analyse des noms des listes aux élections régionales 2010 (par @MattiSG, @flo_sugar, @FrenchKPI et @CifuentesAura)
Ce projet présente une analyse des éléments de langage utilisés par les listes électorales aux régionales 2010… et des surprenants regroupements qui apparaissent entre partis parfois très éloignés.
- Le charcutomètre (par @cq94 et @noirbizarre):
L’idée de cet outil est d’analyser la description des nouveaux cantons publiée au Journal Officiel. Plus la description est longue, plus le canton est donc compliqué et potentiellement « charcuté ». Ce sont les cantons sub-communaux qui sont les plus intéressants car le découpage y est potentiellement arbitraire.
En regardant ces descriptions, une autre idée est apparue… la détection des « détours » par les doublons dans les noms de rues servant de limite. En effet, lorsqu’on quitte une rue, pour y revenir un peu plus loin on en général fait un détour.
Deux scripts ont été utilisés pour récupérer automatiquement le contenu de la centaine de décrets publiés au JORF, en extraire la description textuelle des cantons, puis analyser le nombre de segments et le nombre de doublons.
La sortie est pour l’instant un fichier CSV dont le code est disponible sur https://github.com/cquest/charcutometre
- Étude des circonscriptions législatives propices à la bascule politique d’un camp à l’autre (non terminé) (par Benjamin Ooghe Tabanou, employé Médialab CDSP et David Gayou de l’association Regards Citoyens):
Il s’agissait ici d’étudier les circonscriptions législatives propices à la bascule politique d’un camp à l’autre. La visualisation réalisée (ci-dessous) est un « work in progress » indiquant le virement des circonscriptions d’un parti à l’autre, d’une législative à la suivante.
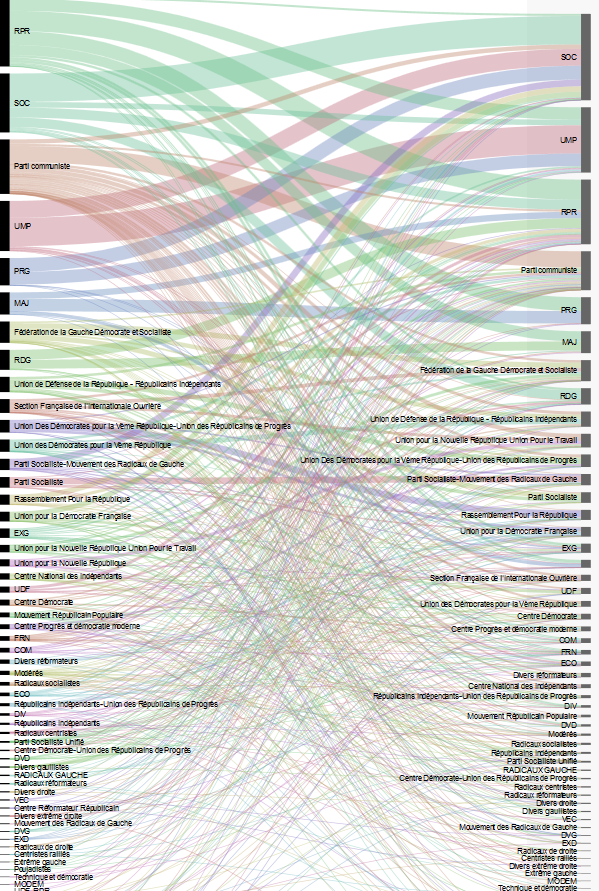
Data visualisation : http://www.regardscitoyens.org/pad-preview/#https://pad.lqdn.fr/p/od-elections
- Caractérisation du vote radical (par @_stadius, Valérie Segond, Jules Mourier, Jean-Marc Gailis et Nathan De Rouck):
Le but de l’atelier était de regarder l’évolution du vote « anti-système », d’essayer de voir si la gauche radicale attire davantage le vote contestataire que l’extrême droite ou vice versae, et de voir si le vote anti-système est corrélé ou non avec des facteurs socio-économiques tels que le niveau et progression du chômage et la perte d’emplois industriels.
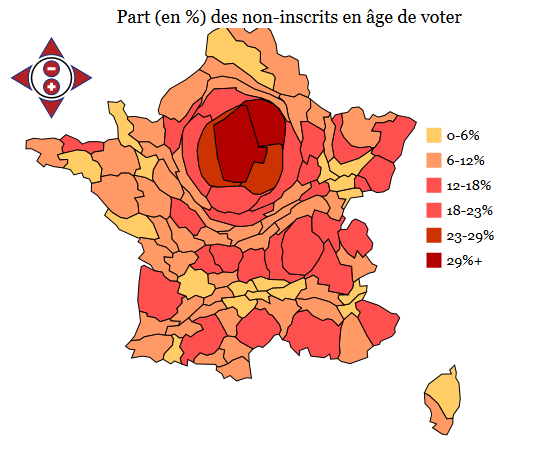
Un premier rapprochement de deux jeux de données différents (électoral et démographique) a été de regarder le nombre d’inscrits, département par département, pour les élections régionales de 2010 et de comparer le nombre d’habitants des départements correspondant en âge de voter. Puis le groupe de travail a visualisé l’écart entre les inscrits et les habitants qui est visible sur le cartogramme interactif ci-dessous:
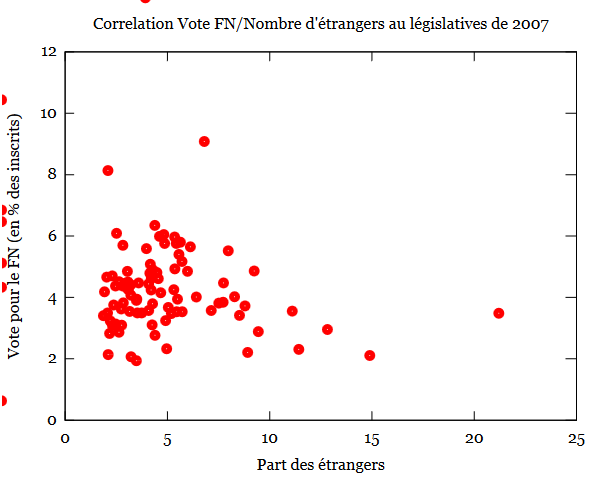
Une deuxième approche a été d’analyser la corrélation entre le vote FN pour les élections législatives de 2007 et le nombre d’étrangers dans le département (cf. graphique ci-dessous):
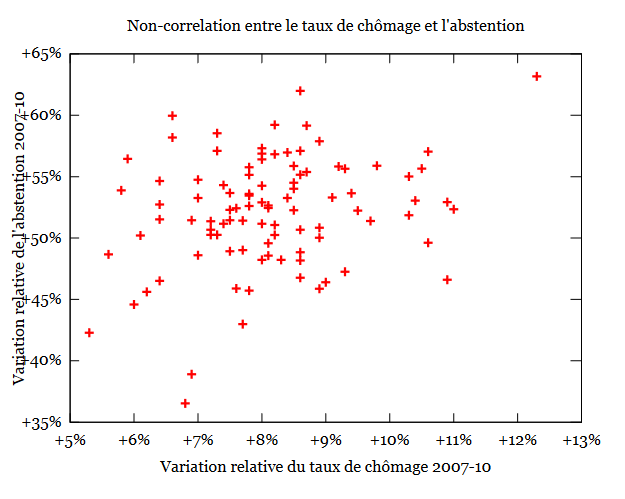
 Le groupe de travail s’est ensuite penché sur l’étude de la variation de l’abstention entre les législatives de 2007 et la variation du taux de chômage pour la même période. La question que le groupe s’est posée est: « Est ce que la vague d’abstention aux régionales de 2010 est liée à la montée du chômage ? »
Le groupe de travail s’est ensuite penché sur l’étude de la variation de l’abstention entre les législatives de 2007 et la variation du taux de chômage pour la même période. La question que le groupe s’est posée est: « Est ce que la vague d’abstention aux régionales de 2010 est liée à la montée du chômage ? »
Comme le montre le graphique ci-dessous, il n’y a pas de corrélation:
 Enfin, le groupe de travail a regardé si la montée du vote anti-système (extrême-droite, gauche radicale) est corrélée ou non avec la montée du chômage. Une légère corrélation positive a été identifiée entre le vote gauche radicale et la montée du chômage (enveloppe qui monte légèrement) et aucune corrélation entre le vote extrême-droite et la montée du chômage (cf. graphe ci-dessous):
Enfin, le groupe de travail a regardé si la montée du vote anti-système (extrême-droite, gauche radicale) est corrélée ou non avec la montée du chômage. Une légère corrélation positive a été identifiée entre le vote gauche radicale et la montée du chômage (enveloppe qui monte légèrement) et aucune corrélation entre le vote extrême-droite et la montée du chômage (cf. graphe ci-dessous):
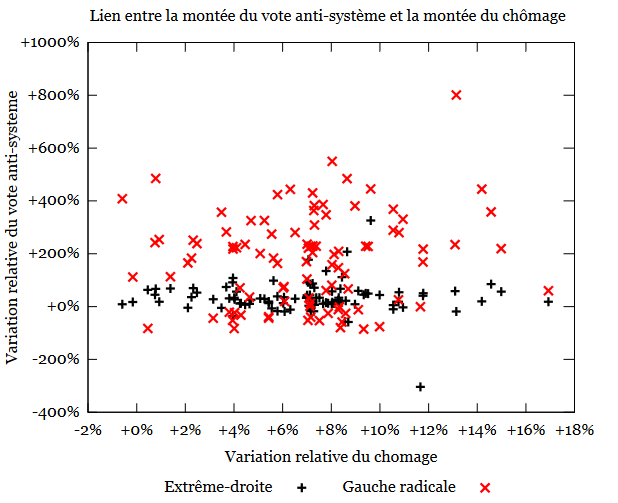
Les résultats du groupe de travail ne sont pas concluants. Le choix initial a été lié à la facilité dont les données ont été identifiées ainsi que leur granularité. A première vue, la montée du chômage n’est pas un facteur, ou un facteur peu important sur le vote anti-système. Toutefois, le groupe de travail souhaite revérifier cette hypothèse en comparant plusieurs jeux de données d’élections, consécutives de même type, et les comparer avec d’autres facteurs, comme les présences de catégories socio-professionnelles sur les territoires ou la distribution des revenus dans les circonscriptions.
Les résultats de ces prochains travaux seront publiés sur le blog stadius.fr.
- Datacamp 2015 (par @joelgombin et @antoinejardin):
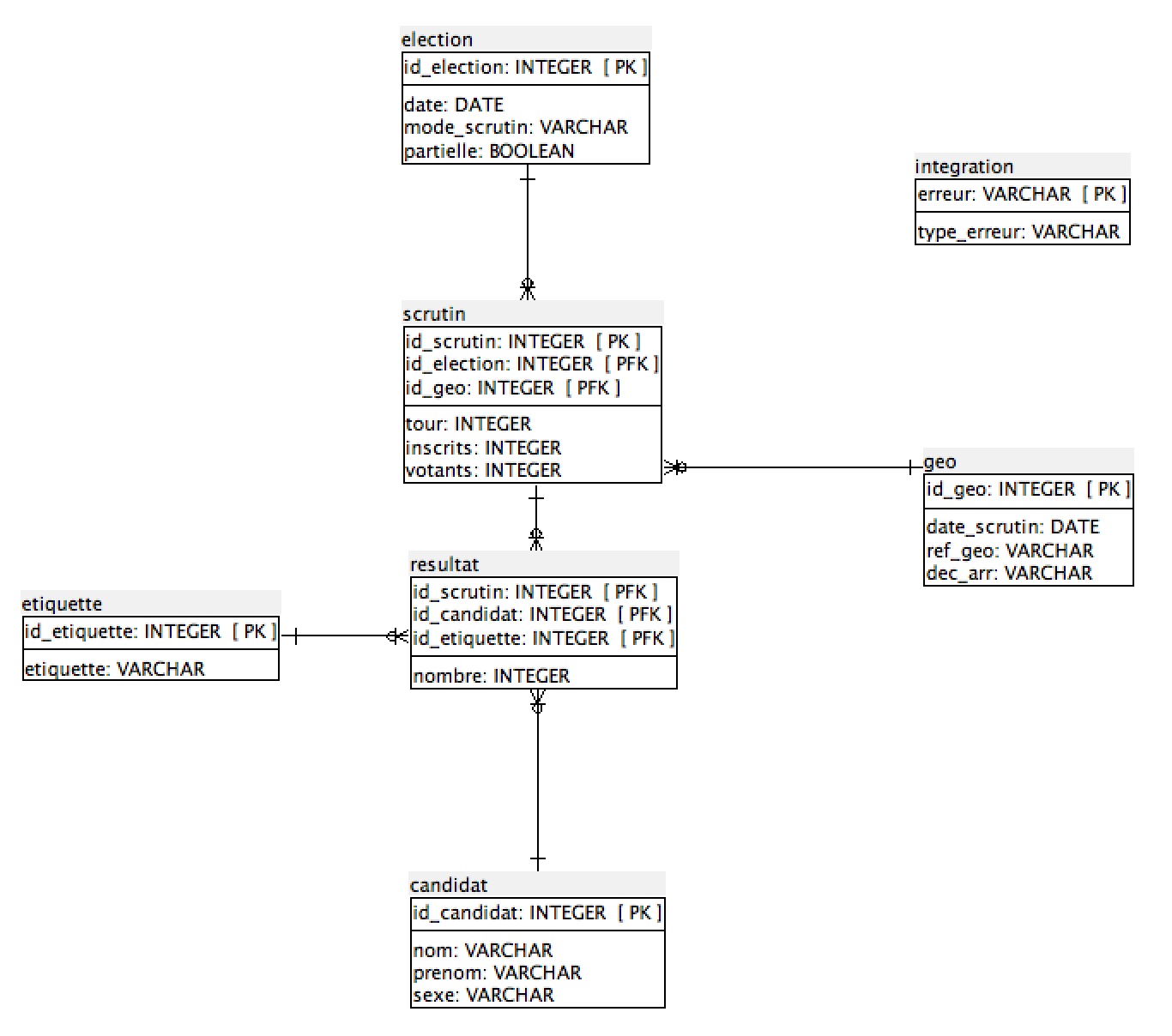
L’objectif de ce projet était de construire une base de données relationnelle des résultats électoraux en France. Le modèle est pensé pour être réutilisable avec peu de modification pour d’autres pays. Il doit permettre l’ajout de résultats anciens à mesure qu’ils sont numérisés ainsi que l’ajout des futurs résultats électoraux. Il s’appuie sur les nomenclatures officielles des différentes sources de données pour permettre les rapprochements, fusions et correspondances.
Le groupe de travail a utilisé les résultats électoraux les plus fins disponibles. Il s’est appuyé sur les nomenclatures INSEE des communes en prenant compte de leur évolution dans le temps. Les nuances d’origines des candidats sont prises en compte mais vérifiées et « recodées » lorsque c’est nécessaire. Ce travail s’appuie sur l’historique des résultats électoraux déjà stocké par différentes institutions.
Le projet dispose d’un premier design de la structure de la base de données et des premiers éléments des fichiers sources.
Conclusion
Cette journée du 23 février a rassemblé plus de 80 participants d’horizons divers: data scientists, data journalistes, start-up, étudiants, chercheurs et administrations se sont rassemblés afin de travailler autour des données élections mises à disposition sur la plateforme data.gouv.fr.
Les travaux menés par ces groupes de travail ont permis de traiter des sujets aussi variés que l’Analyse des noms des listes aux élections , le découpage des nouveaux cantons, la création d’une base de données relationnelle des résultats électoraux en France, l’analyse des données socio-démographiques et du comportement électoral, la géolocalisation des lieux suscitant l’intérêt médiatique en rapport avec les élections
Au delà de la qualité des travaux présentés, cette journée a permis aux porteurs de projets d’échanger librement avec l’ensemble des producteurs de données qui se sont mobilisés pour mettre à disposition des données de qualité.
Un grand merci aux participants ainsi qu’aux producteurs de données qui se sont prêtés au jeu le temps d’une journée.
Ping : Civic Tech : et si l’innovation inversait le sens du pouvoir ? | Trop Libre - Une voix libérale, progressiste et européenne
Ping : Civic Tech : et si l’innovation vous rendait le pouvoir ? | Contrepoints
Ping : Civic Tech : et si l’innovation vous rendait le pouvoir ? | LeSScro