

Le 26 janvier 2015, la Paillasse a accueilli dans ses locaux parisiens le premier hackathon dédié aux données de santé, co-organisé par l’Assurance Maladie et la mission Etalab. Retour sur cet évènement, les projets et les enseignements de cette journée.
Le DAMIR, un outil pour suivre les dépenses de santé
En amont de cette journée, l’Assurance Maladie (CNAMTS) a mis à disposition sur data.gouv.fr une première version agrégée de la base DAMIR utilisée pour le suivi des dépenses de santé en France. Cette ouverture avait été annoncée dans les conclusions de la Commission Open Data santé.
La base DAMIR est l’une des composantes du système national d’information inter-régimes de l’assurance maladie (SNIIRAM). Ce système est qualifié par Mr Nicolas Revel (directeur de la CNAMTS) de « probablement la plus grande base de données médico-économiques dans le monde ». Elle est en effet alimentée chaque année par 1,2 milliard de feuilles de soins, 500 millions d’actes médicaux et 11 millions d’hospitalisation.
Un hackathon pas comme les autres : open data + data sciences
Etalab s’est associée à l’Assurance Maladie pour préparer l’organisation de ce hackathon d’un genre inédit. En effet, la plupart des évènements que nous animons (Open Data Camps) concernent des jeux de données déjà disponibles en open data (sur l’accidentologie routière, par exemple).
Cette fois la démarche fut légèrement différente, puisqu’elle s’est inscrite en amont de l’ouverture : la plupart des participants auront découvert les détails du DAMIR lors de cette journée. Le volume de la base (l’équivalent d’un fichier CSV avec 1,5 milliard de lignes…) imposait aussi la mise en place d’une architecture technique dédiée.
L’équipe des data scientists rattachée à l’administrateur général des données, Henri Verdier, et l’équipe de la direction statistique de la CNAMTS ont joué un rôle majeur en amont et durant l’évènement. Elles ont préparé les données du DAMIR, les ont documentées (notamment via un wiki), ont identifié des jeux de données complémentaires déjà ouverts (le répertoire partagé des professionnels de santé, les fichiers de population protégée, les données du PMSI fournies par l’ATIH, des données démographiques, …).
Des participants issus de l’ensemble de la filière santé
Plus de 80 personnes ont participé à cette journée de développement. Parmi eux, des représentants d’organismes publics du secteur (CNAMTS, ANAP, HAS, DREES, …), des entreprises spécialistes du domaine (GE Healthcare, Celtipharm, Mipih, Cap Gemini Consulting, Jalma, Epiconcept…), des assureurs (Covea), des start-ups du monde médical (BePatient) et des objets connectés (Withings). Ils ont été accompagnés toute la journée par les experts métiers de l’Assurance-Maladie et l’équipe d’Etalab.
Une dizaine de pitchs se sont succédés en début de journée. La plupart des projets étaient formulés sous la forme de questions. Quelques exemples [liste complète]:
– comment évoluent les restes à charge du patient en fonction du régime d’exonération ?
– peut-on établir un lien entre l’offre de soins (par ex. la densité de médecins) et la pratique des dépassements d’honoraires ?
– une sous-consommation de la médecine de ville est-elle géographiquement corrélée avec une surconsommation des urgences ?
– la demande de soins est-elle liée à l’offre ? (ou: va-t’on plus souvent chez le médecin quand l’offre de soins est plus abondante ?)
– observe-t-on une corrélation entre les dépenses médicales et les indicateurs de l’état de santé issus des objets connectés comme le niveau d’activité et l’IMC (indice de masse corporelle) ?
– comment évolue géographiquement la permanence des soins ?
– peut-on comparer les campagnes de dépistage du cancer organisé vs. le dépistage individuel ?
– les dépenses de santé sont-elles corrélées à l’indice de développement humain (IDH) par région ?
– la prise en charge et le traitement de l’alcoolisme sont-ils uniforme sur le territoire ?
Enfin, un dernier groupe s’était donné un défi : peut-on ré-identifier un patient ou un professionnel de santé à l’aide des données mises à disposition ce jour-là. Réponse négative en fin de journée : ils n’ont pas réussi à identifier de problèmes d’anonymisation.
Lors de ce hackathon, plus d’un million de requêtes ont été traitées par le serveur (postgresql), près de 650 Go de données transmis aux participants via les 200 mètres de câbles du réseau local ethernet gigabit.
Les résultats
A l’issue d’une journée d’intenses développements, à peine interrompus par une visite impromptue de Thierry Mandon, secrétaire d’Etat à la modernisation de l’Etat et à la simplification, les groupes ont été invités à présenter l’état d’avancement de leurs travaux devant Mme Marisol Touraine, ministre de la Santé et des affaires sociales, entourée de M Nicolas Revel (CNAMTS) et Mme Laure de la Bretèche (secrétaire générale à la modernisation de l’action publique).
Certains projets ont obtenu des résultats très concrets. Ainsi, concernant le lien entre offre de soins et consommation par département [graphique ci-dessous], il a été établi que lorsqu’on augmente la densité de médecins de 100 pour 100 000 habitants dans un département, le nombre de visites chez un généraliste par affilié augmente de 0,5 par an. Cet effet prend en compte la structure par âge de la population locale et les revenus des ménages dans le département [résultats détaillés].
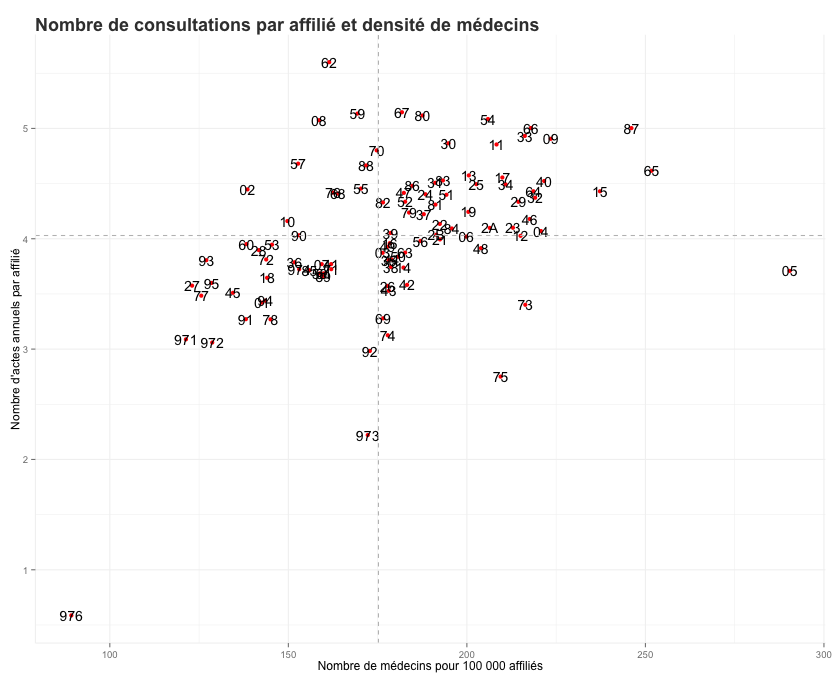
Pour d’autres groupes, la journée aura permis de réaliser une première visualisation ou encore d’identifier les jeux de données qui manquent pour répondre à leur problématique.
Pour tous, la journée aura permis d’en découdre, par la pratique, avec les données du DAMIR.
Les enseignements de la journée
A l’issue de la journée, Nicolas Revel a ainsi annoncé la mise à disposition des données sur data.gouv.fr d’ici février, et la volonté de CNAMTS de poursuivre ces démarches collaboratives.
Ce hackathon aura permis de valider plusieurs hypothèses:
– même des données complexes comme celles du DAMIR peuvent être appréhendées en une journée, pour peu qu’un réel effort de préparation et de documentation ait été réalisé en amont ;
– le croisement entre l’open data et les data sciences est prometteur, il permet de s’attaquer à des sujets de politique publique avec de nouvelles approches basées sur les données ;
– sur des sujets complexes – et inédits – comme celui de l’ouverture des données de santé, rien ne vaut la pratique pour se mettre en mouvement : c’est en mettant à disposition les données qu’on perçoit l’intérêt de l’open data.
Mais l’essentiel est peut-être ailleurs : en une journée, on a pu voir le prototype de ce que pourrait être un véritable écosystème de la donnée de santé, on a vu des acteurs passionnés par leurs problématiques nouer de nouvelles formes de coopération, se comprendre aisément, forger, peut-être, des partenariats à venir. On a pu voir la silhouette de ce que pourrait être une ouverture contrôlée et apaisée, et le dessin de ce que pourraient en être les conséquences. On a senti se lever une dynamique. A poursuivre…

Ping : lecrip.org | Cercle de réflexion de l'industrie pharmaceutique